Filtrar
9 Questões de concurso encontradas
Página 1 de 2
Questões por página:
Considerando os problemas citados, analise as afirmativas a seguir.
I. Em uma tabela binária esparsa, que representa uma base de dados de transações de clientes, em que as colunas representam cada produto e as linhas cada transação, verifica-se que, frequentemente, três das colunas apresentam simultaneamente o valor 1 para vários registros. Este tipo de análise é um problema de detecção de valores discrepantes.
II. A identificação de consumidores que são similares entre si, para uso no contexto de aplicação de promoções orientadas, constitui um problema de segmentação de dados.
III. O problema de classificação de dados pode ser considerado como supervisionado, pelo fato das relações entre as classes definidas e os demais atributos dos dados serem “aprendidas” pelo modelo.
Está correto o que se afirma em
Em uma pesquisa sobre caraterísticas de condenados em uma determinada Vara Federal, uma amostra aleatória de condenados de tamanho n foi tomada e investigou-se nos respectivos processos suas características. Os resultados observados recebiam avaliação dos psicólogos em notas em uma escala até 7 pontos. As notas se referem às características: C1, C2, C3, C4 e C5. Os resultados foram tabulados e a matriz de correlação R construída. Após ser aplicada a Análise Fatorial na matriz R, obtiveram-se os resultados tabelados a seguir:
Análise Fatorial
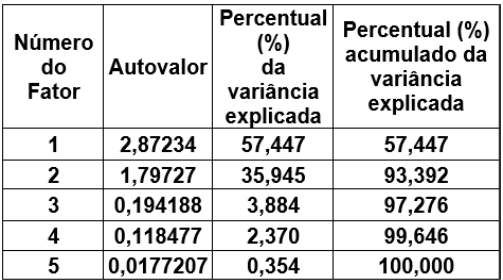
Pesos dos fatores após rotação Varimax
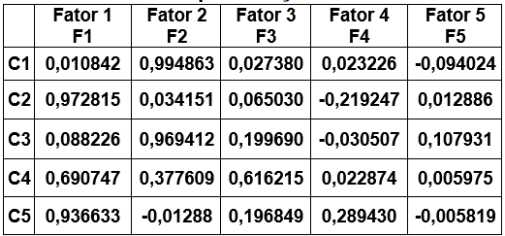
Então, é correto afirmar que
A lógica fuzzy é uma extensão da lógica booleana. Embora as técnicas de controle possam ser implementadas por modelos matemáticos, as implementações baseadas na lógica fuzzy apresentam um melhor desempenho.
Qual é o aspecto fundamental da lógica fuzzy?
