Questões de Concurso
Filtrar
2.928 Questões de concurso encontradas
Página 47 de 586
Questões por página:
A fórmula utilizada mundialmente para fazer o cálculo do índice de massa corporal (IMC) feminino ou masculino é: IMC = Peso dividido pela altura ao quadrado (peso/altura2 ). A tabela seguir foi criada no LibreOffice Calc em ambiente Windows 8.
A coluna E deve indicar para cada pessoa cujo nome está na coluna A o seu IMC. A fórmula correta que deve ser digitada na célula E2 deve ser:
A tabela a seguir foi criada no LibreOffice Calc em ambiente Windows 8:
Na célula B7 a seguinte fórmula foi digitada: =SOMA(B2:B5)/CONT.NÚM(B2:B5). Qual valor deverá aparecer na célula B7?

Na célula C8 foi digitada a seguinte fórmula: =ÍNDICE(C2:C6;CORRESP(MENOR(B2:B6;1);B2:B6;0))
Qual resultado será apresentado na célula C8?
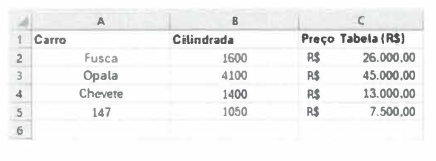
A tabela mostrada a seguir foi feita em Excel, versão 2010, em português-BR.
A fórmula seguinte foi digitada na célula A6:
=CONCAT(I N DIRETO("a"&CORRESP(MÁXIMO(C 1 :C5);
C1 :C5));TEXTO(INDIRETO("b"&CORRESP(MÁXIMO(C1
:C5);C1 :C5));"-0000"))
Qual conteúdo será mostrado na célula A6?
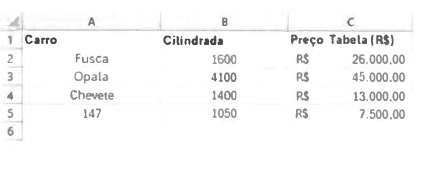
A tabela mostrada a seguir foi feita em Excel, versão 2010, em português-SR.
A fórmula seguinte foi digitada na célula A6:
=CONCAT(INDIRETO("a"&CORRESP(MÁXIMO(C1 :C5);
C1 :C5));TEXTO(INDIRETO("b"&CORRESP(MÁXIMO(C1
:C5);C1 :C5));"-0000"))
Qual conteúdo será mostrado na célula A6?
