Questões da prova:
CESGRANRIO - 2024 - BNDES - Analista - Ciência de Dados
limpar filtros
70 Questões de concurso encontradas
Página 1 de 14
Questões por página:
Questões por página:
Concurso:
BNDES
Disciplina:
Engenharia de Software
Em aplicações modernas de Processamento de Linguagem Natural, usando Grandes Modelos de Linguagem (Large Language Models – LLM) é comum a necessidade de usar informações relevantes que estão em documentos novos e privados, que não foram usados no pré-treinamento dos modelos de LLM. Considerando que esses documentos podem ser longos e em grande quantidade, que o tamanho do contexto usado na chamada à Application Programming Interface (API) da LLM é limitado, e ainda pensando que os custos de processar são muitas vezes calculados por quantidade de tokens, foi desenvolvida a técnica conhecida como Retrieval Augmented Generation (RAG).
Considerando-se esse contexto, qual é a característica da técnica RAG?
Considerando-se esse contexto, qual é a característica da técnica RAG?
Concurso:
BNDES
Disciplina:
Programação
Um analista financeiro está trabalhando com um conjunto de dados de clientes de um banco, armazenados em um DataFrame Pandas chamado  Esse DataFrame possui as seguintes colunas: Nome, Idade, Dívida, Renda e Status. O analista deseja criar um novo DataFrame que contenha apenas os nomes e as dívidas dos clientes que possuem uma dívida maior que R$ 10.000,00, com o objetivo de gerar um relatório específico.
Esse DataFrame possui as seguintes colunas: Nome, Idade, Dívida, Renda e Status. O analista deseja criar um novo DataFrame que contenha apenas os nomes e as dívidas dos clientes que possuem uma dívida maior que R$ 10.000,00, com o objetivo de gerar um relatório específico.
Considerando-se esse contexto, qual das seguintes linhas de código em Python com Pandas seleciona corretamente as colunas Nome e Dívida do DataFrame e também filtra apenas as linhas em que a dívida dos clientes seja superior a R$ 10.000,00?
e também filtra apenas as linhas em que a dívida dos clientes seja superior a R$ 10.000,00?
Esse DataFrame possui as seguintes colunas: Nome, Idade, Dívida, Renda e Status. O analista deseja criar um novo DataFrame que contenha apenas os nomes e as dívidas dos clientes que possuem uma dívida maior que R$ 10.000,00, com o objetivo de gerar um relatório específico. Considerando-se esse contexto, qual das seguintes linhas de código em Python com Pandas seleciona corretamente as colunas Nome e Dívida do DataFrame
e também filtra apenas as linhas em que a dívida dos clientes seja superior a R$ 10.000,00?
Concurso:
BNDES
Disciplina:
Programação
Um desenvolvedor está criando uma rede neural de 3 camadas, usando PyTorch para classificar amostras descritas por um vetor com 10 elementos. Ele já definiu parte da rede, conforme o extrato de código abaixo, e pretende definir a camada oculta como sendo composta de 5 nós, utilizando a função de ativação ReLU.

Considerando-se esse contexto, qual das linhas de código a seguir deve ocupar o comentário “#AQUI CRIAR CAMADA OCULTA COM 5 NOS E RELU” para definir corretamente a camada oculta?
Considerando-se esse contexto, qual das linhas de código a seguir deve ocupar o comentário “#AQUI CRIAR CAMADA OCULTA COM 5 NOS E RELU” para definir corretamente a camada oculta?
Concurso:
BNDES
Disciplina:
Estatística
Um cientista de dados está utilizando SHapley Additive exPlanations (SHAP) para entender a importância das variáveis em um modelo de aprendizado de máquina que prevê a probabilidade de um cliente deixar de ser assinante de um serviço (churn). Considere o seguinte conjunto de dados simplificado com três características para um cliente específico:
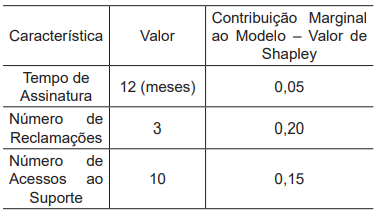
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
A previsão base do modelo, que representa a probabilidade estimada de um cliente se tornar um churn quando nenhuma das características individuais é considerada, é de 0,30.
Considerando-se esse contexto, qual é a probabilidade prevista pelo modelo para que esse cliente deixe de assinar o serviço?
Concurso:
BNDES
Disciplina:
Engenharia de Software
Um pesquisador de ciência de dados foi encarregado de analisar a capacidade de um modelo de aprendizado de máquina em prever se um cliente é bom pagador. Para isso, possuía um conjunto de dados de testes rotulado, sobre o qual aplicou o modelo e obteve a matriz de confusão a seguir:
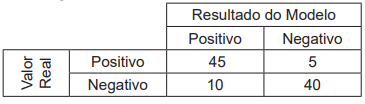
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
